大模型专栏--什么是大模型 Token
本篇文章中,将介绍大模型 token。包括 token 是什么,为什么会有 token 以及大模型为什么使用 Token 计费。
从自然语言处理(NLP)理解
分词器
分词器(Tokenizer)是自然语言处理(NLP)中的一个重要组件,用于将文本分解成更小的单元(通常是词或子词)。分词是许多 NLP 任务的基础,包括文本分类、情感分析、机器翻译等。
由分词器切分出来的每一个小块,便是一个 token。
比如说下面的情形:
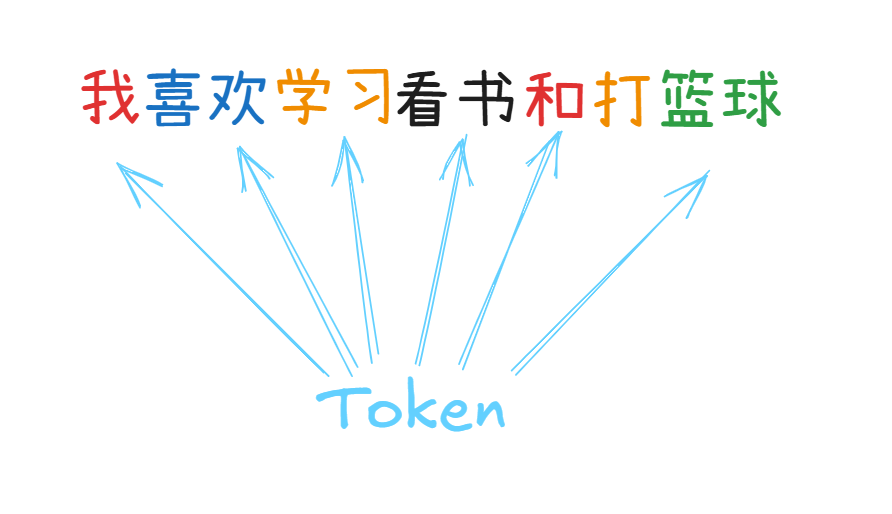
可能 “我” 是一个 token,”喜欢” 是一个 token,“,” 是一个 token。诸如此类的像单个汉字,两个汉字组成的短语,标点符号,三个字母组成的单词或者词缀等可能都是一个 token。
说到这里,可能还是有些不太明白,为什么 ”我“ 是一个 token,而 ”篮球“ 也是一个 token?通俗理解
人脑认知
首先,先看下面一副图片:

如果现在让你快速念这几个字?孔子不认识,庄子不认识,老子也不认识。
如果让这几个字出现在词语里?像下面这样:

会瞬间清晰很多,一下子就能念出来!
之所以会出现这样的情况,是因为大脑也会偷懒,在日常认知和生活中,将这些有含义的短语或者词语作为一个整体来对待。除非面对特殊情况时,否则不会一个一个去搞清楚发音和用途。这就直接导致了看词语熟悉,但是单看字就很陌生的认知情况出现。
而这样做的原因是会节省脑力,在日常生活中,几乎不存在单独出现的情况,所以大脑有意识的规避了一些生僻字。例如下面这个短语:

如果一个一个字去看,大脑就需要处理 7 个字之间的语义关系,如果按照短语或者词语的方式处理,那么只需要处理 4 个部分之间的语义关系。从而提高效率,节省脑力。
大模型认知
既然人脑可以通过上述行为,节省脑力,提高效率。那么大模型自然也能这么做,所以就有了分词器。
专门负责将一段文本,拆分成为一个个大小合适的 token。不同的人在不同的环境中对短语和词语的分组是不同的,比如语言学家和普通上班人之间。语言学家对一个个的生僻字更为敏感,上班族为了处理不同的业务工作。所以大脑有意识的忽略了生僻字的处理。
在大模型中,也有此类情况。根据不同的分词器,将一段相同的文本切分之后的效果也是不同的。
因此,在面对不同用途的情形时。文本切分越合理。大模型处理越轻松。分词器原理
那么分词器到底时如何分词的呢?默认人类大脑学习过程。其中一种方法大概是:
在大模型分词器统计了大量文本数据之后,发现 “今天” 两个字经常在一起出现。而 “今” 这个字出现的频率较低。在大模型分词器分词时,会优先把 “今天” 作为一个 token。
在识别到了 “今天” 这个词语之后,会将 “今天” 打包成为一个 token。并赋予对应的数据编号。比如 “今天” == 19978。将 token 和 编号的关闭保存在一个映射关系表里:类似下面这样。
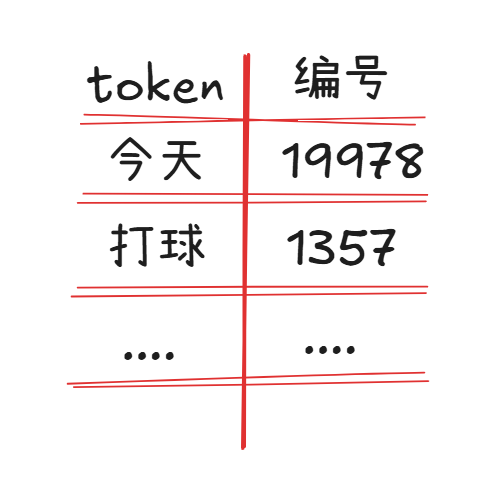
当词语再次出现时,大模型便会查找在关系表里查询,在输入和输出时,面对一堆数字编号即可。之后由分词器根据关系表转为人类能看懂的文字和符号。
类比于人脑,大模型可能有一个非常庞大的词汇表,可能有 5 万或者 10 万个。包含我们日常见到的各种字或词,符号等。
Token 切分演示
网站:https://tiktokenizer.vercel.app/
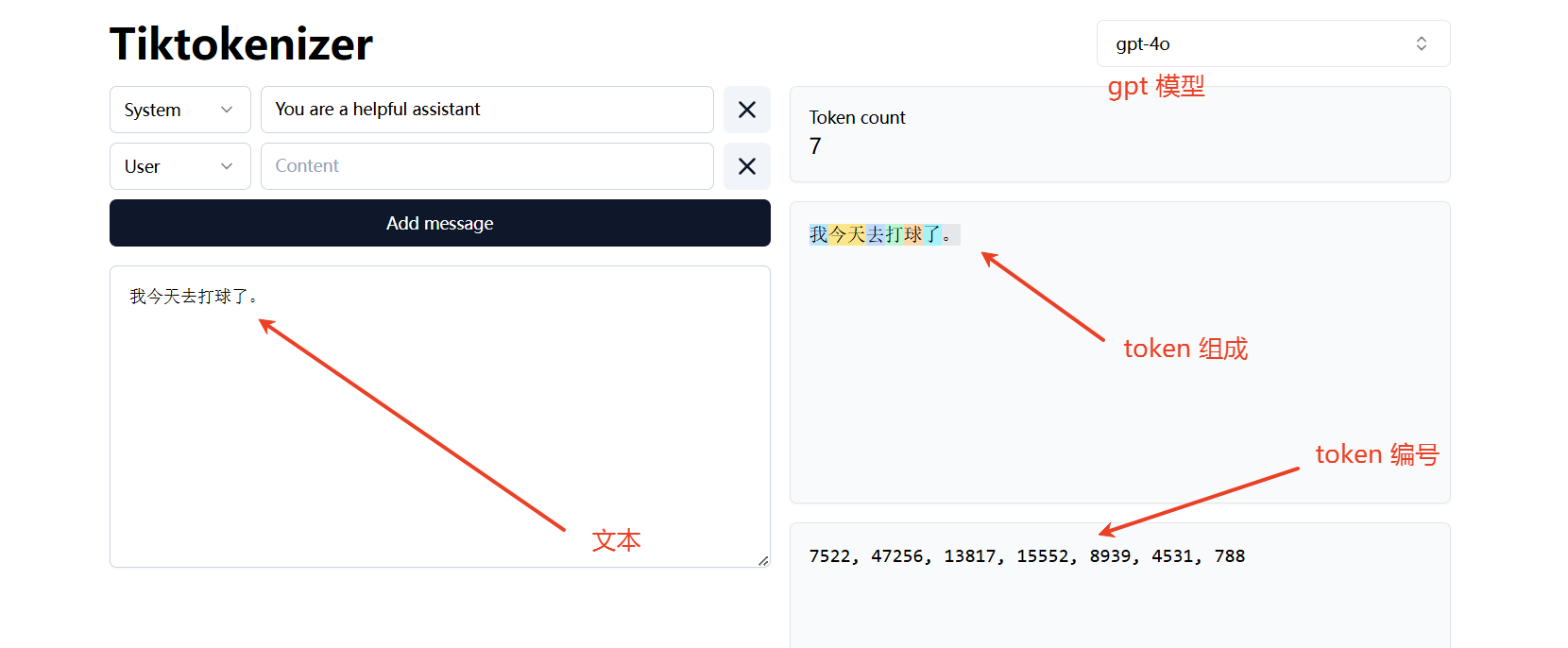
在这个网站中,我们可以看到不同的模型在面对同一段文本时的 token 切分、组成,以及 token 编号情况。
gpt 模型 Token
deepseek-r1 模型
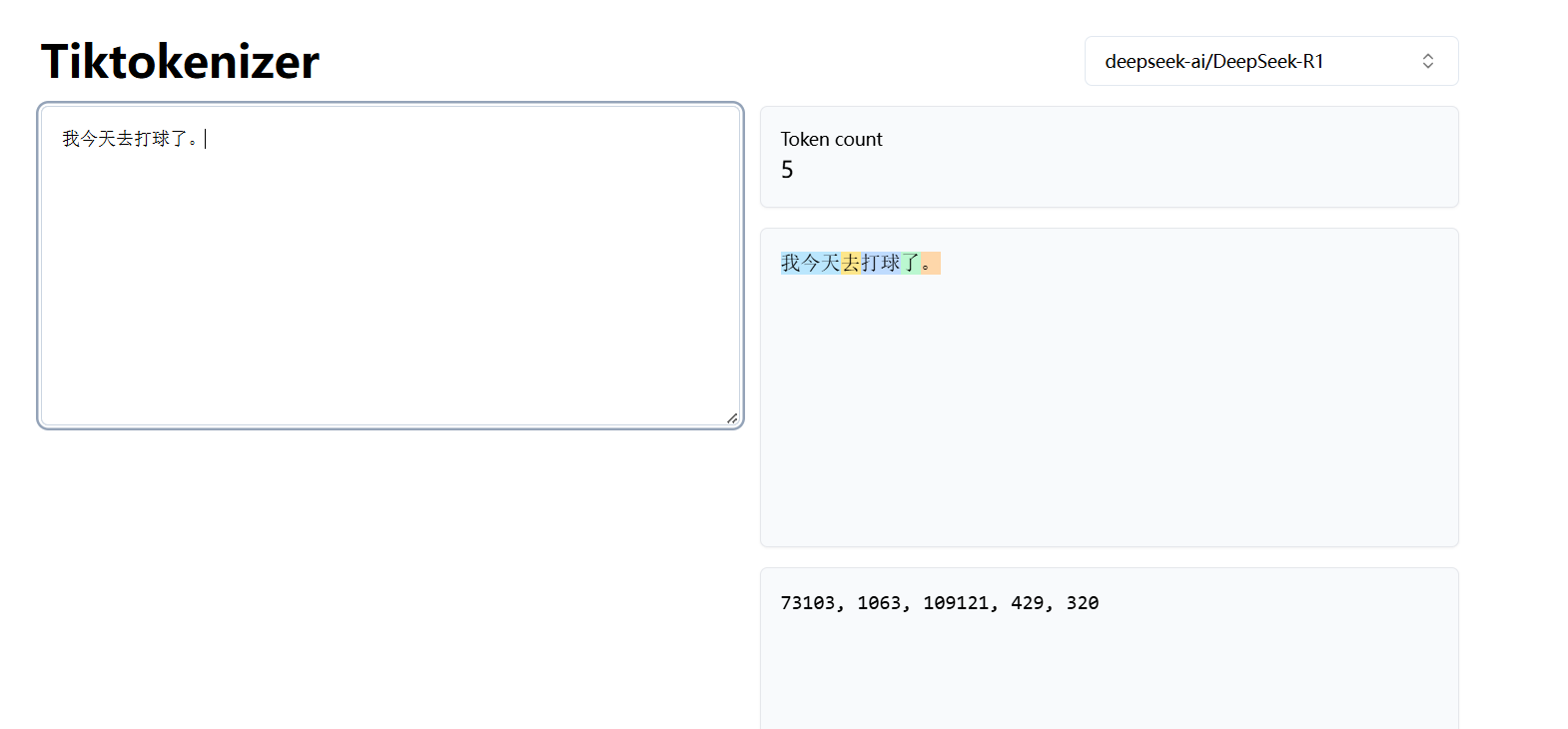
可以看到,不同的模型在面对同一段文本时,切分的 Token 也是不同的。
Token 总结
在大模型看来,所有的文字都是一个个 Token,而大模型正是通过计算 Token 之间的关系,来推断初下一个 Token 最有可能是哪一个。
大模型 Token 计费
这也是为什么所有大模型厂商使用 token 计费的原因。token 的数量决定了大模型的计算量。