大模型专栏--AI RAG
RAG(Retrieval-Augmented Generation )介绍
之前的文章中已经大概介绍了 RAG 是什么,并且介绍到了当前 LLMs 的一些缺点,也是 RAG 技术的背景来源。 在这篇文章中,将深入挖掘一下 RAG 的技术原理和当前现状。
首先我们在从头复述一下之前所说的一些关于 RAG 的内容,并对其中的一些描述进一步细化:
当前 LLMs 存在的问题
随着大模型的发展,其已经被用于到业务场景中。但是目前也存在一些较为突出的问题。
-
(新鲜度问题)知识缺乏:
- 大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。模型难以处理实时信息,因为训练过程耗时严重且成本较高。模型一旦训练完成,就难以获取和处理新信息。
- 随着数据越来越多(参数和 Token 越多),大模型的训练成本也越来越高。(目前参数量最大的模型可能是来自于马斯克的 Grok-1 模型,参数量高达 3140 亿。)
-
数据安全:
- 因为 GPT模型的数据问题,OpenAI 已经多次收到侵犯隐私数据的投诉。
- 在企业内部,数据安全至关重要,没有企业愿意把自身数据上传到第三方平台训练大模型。
-
(幻觉)偏见问题:
- 幻觉英文术语成为 Hallucination,既一本正经的话说八道。如果大家经常使用大模型,可能会发现大模型经常返回错误的信息;其来源可能是基于多个基本元素,借助 NLP 能力,生成的看似符合逻辑,但违背人类认知常理的输出。
- 从某种理论上来说,这种幻觉的表达是某种涌现能力的体现,体现了大模型自身的创造力。举个例子,人做梦的场景,可能是基于白天见到的某类事物引发的,而基于人类白天的认知,我们会自我修正,意识到这是不符合逻辑的。随着 LLMs 的发展,可能人类能自行调整大模型的 input 控制大模型的涌现能力。
RAG
基于上面描述的 LLMs 的缺点,RAG 技术应用而生,不能说是最好的解决方案,但是是目前最有效的解决方案。
RAG:全程是 Retrieval Augmented Generation,中文译为检索增强生成。从名字中我们可以看到他的实现逻辑是
$$ 检索 -> 增强 -> 生成 $$
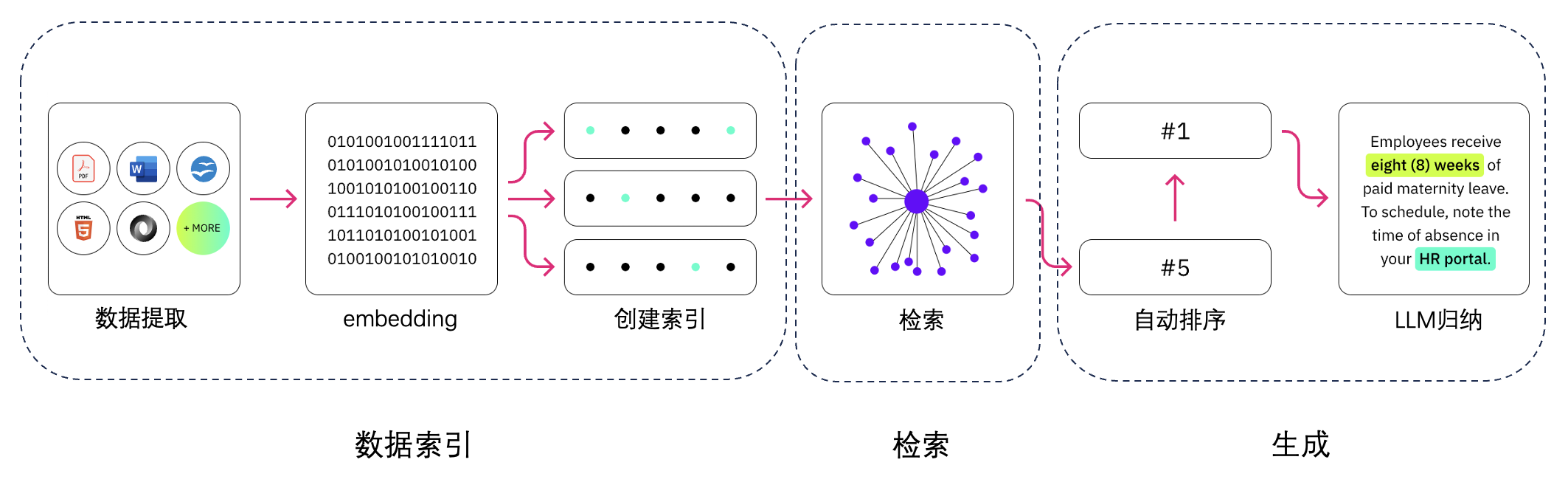
检索
检索流程示意图:
从上面看到,RAG 检索分为两部分,一是数据预处理,二是向量数据检索。
向量化
我们先来了解一下什么是向量化,以及为什么要向量化?
正如示意图中描述的那样:向量化是为了将数据转化成计算机可以识别的数据形式。
向量是一个线性代数中的数学名词,在不同的学科有不同的含义。在计算机领域中表示的是一个有序列表。在 AI 领域中,将文本数据转换成向量的过程就像把书里的文字变成一种特殊的密码,让计算机能够读懂和处理。
向量 Embedding 的核心是指在数学空间中将单词、句子甚至整个文档表示为密集的低维向量的过程。其封装了单词之间的语义关系,语义相似的词在向量空间中越近,并使算法能够理解它们的上下文含义。让 LLMs 能够利用嵌入在文本数据中的丰富语义信息,生成更连贯和上下文更合适的响应。
向量对大模型的影响
向量在 LLMs 中的主要应用方式体现为向量数据库,对解决 LLMs 的幻觉问题有很大的帮助。也被成为 LLMs 的外脑。
例如,对应下面的三句话:
- “The cat chases the mouse” 猫追逐老鼠。
- “The kitten hunts rodents” 小猫捕猎老鼠。
- “I like ham sandwiches” 我喜欢火腿三明治。
其在向量空间的表示可能为:

LLMs 在处理时那能够理解他们的语义相关性。
张量探索 (引用 1)
基于张量的重排序,来自于 2020 年一篇早期 ColBERT【参考 32】及其改进 ColBERT v2,但是它真正为业界重视起来正是 2024 年初,只是在当时,由于缺乏必要的数据库支持,因此不得不借助于 RAGatouille 这样的 Python 算法封装来提供服务。Vespa 是最早将张量工程化的数据库系统,我们则在年中的时候,为 Infinity 数据库完整地提供了基于张量的重排序能力。目前,基于张量的重排序系统在行业使用并不多,除了 Infra 组件不够多之外,配套的模型缺乏也是重要原因。不过,我们看到,从 2024 年夏天开始,这方面的工作明显进入了快车道,例如针对日文的 JaColBERT【参考 36】,还有 Jina 推出的 Jina-colbert-v2 多语言模型,都提供了为文本数据生成张量的能力。这种模型,对于多模态 RAG 也是个重要促进,可以想象,在 2025年,随着更多的模型就绪,基于张量的重排序,将在大量场景中得到应用。
数据预处理
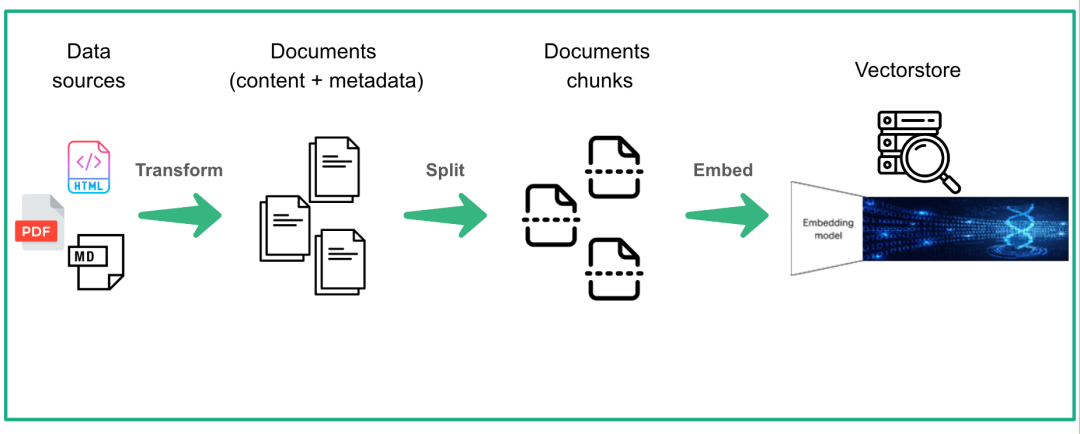
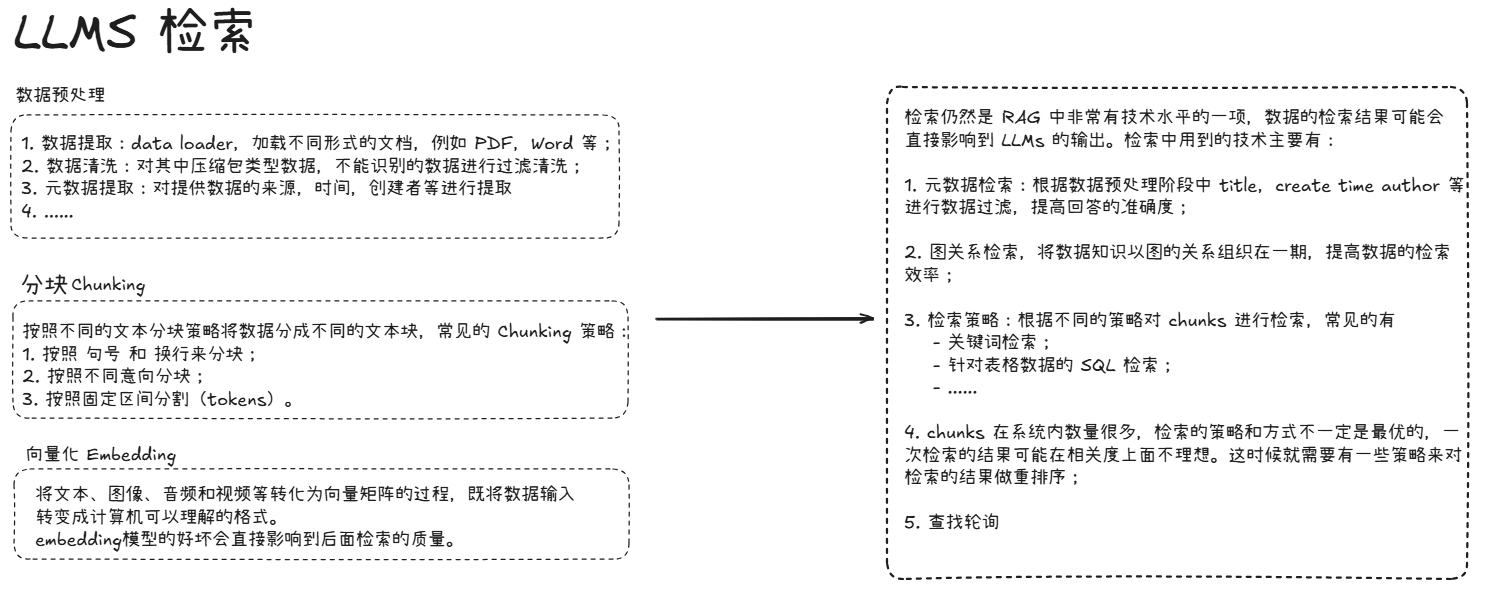
在学术方面,普遍来说:只有保证了数据输入的普适性和准确性才能计算出最准的更准确的数据。
$$ Quality In -> Quality Out $$
目前普遍的处理方式是通过各种 loader 将文本加载进来,再 chunking 之后,利用 Embedding 模型处理。既
$$ Encoder -> Decoder $$
预处理发展
目前 Spring AI Alibaba 提供一系列的 parser 和 reader plugin 来在工程级别支持这一功能。
在模型级别:通过 OCR 模型融合 BERT(BERT 代表双向编码器表示来自Transformer(BERT),用于高效地将高度非结构化的文本数据表示为向量。BERT是一个经过训练的 Transformer 编码器堆栈)来完成对多模态文档的解析。
增强
RAG 中增强是指将检索到的向量信息用作生成模型(即 LLMs)的上下文输入,以增强模型对特定问题的理解和回答能力。 这一步的目的是将外部知识(外脑)融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。 通过增强步骤,LLM模型能够充分利用外部知识库中的信息。
生成
RAG 中的生成和 LLMs 中的生成是同一个意思,既通过 prompt 来让 LLMs 返回输出。其中主要涉及到领域为 Prompt 提示词工程和 LangChain 等的应用框架。
Prompt 是指如何给大模型最佳输入,使其生成最佳回答。在一些 RAG 应用中,通过内置 Prompt 来优化大模型的输出。
LangChain 将 自然语言输入、关联知识检索、Prompt组装、可用Tools信息、大模型调用、输出格式化 等 RAG 应用中的常见动作,组装成一个可以运行的 “链” 式过程。可以直接调用,用来进一步构建更强大的Agent。
Prmpot 工程
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
Prompt 往往和 RAG 的特定领域相关,例如 RAG 是一个 Spring AI Alibaba 问答助手,Prompt 往往更偏向于用户如何使用 Spring AI Alibaba 和使用过程中的一些常见问题等。
RAG 目前面临的问题
-
针对非结构化多模态文档无法提供有效问答。这意味着以 LLMOps 为代表的工作,只能服务纯文本类场景,而像 PDF,PPT,乃至类似图文结合的格式数据,就无法解锁其实际商业价值,这些数据往往在企业内部占据大多数比例。
-
采用纯向量数据库带来的低召回和命中率,从而无法针对实际场景提供有效问答,这主要是因为向量表征不仅缺乏对精确信息的表达,对语义召回也有损耗。
-
RAG 的本质是搜索,它能工作的前提在于根据用户的提问,可以“搜”到答案所在。但是在很多情况下,这个前提不存在,例如一些意图不明的笼统提问,以及一些需要在多个子问题基础之上综合才能得到答案的所谓“多跳”问答,这些问题的答案,都无法通过搜索提问来获得答案,因此提问和答案之间存在着明显的语义鸿沟。