使用 Ollama + Spring AI 搭建 RAG 应用
代码地址:https://github.com/deigmata-paideias/deigmata-paideias/tree/main/ai/ollama-rag
模型:
- Embedding 模型:nomic-embed-text:latest
- Dashscope 模型:deepseek-r1
- Ollama Chat 模型:deepseek-r1:8b
Ollama 和模型下载:https://yuluo-yx.github.io/blog/windows-deploy-ollama3-install-llama3/ Docker 部署 ES:https://github.com/springaialibaba/spring-ai-alibaba-examples/tree/main/docker-compose/es
使用 Spring AI
核心代码实现如下:
ApplicationInit
在这个文件中,主要做的事情是:
- 从
resources/data目录加载 pdf 文件,转为 Resource 资源对象; - 将 Resource 资源对象转化为 Spring AI 的 Document 对象;
- 调用 Ollama 的 embedding 模型,转为向量存储到向量数据库中。
@Component
public class ApplicationInit implements ApplicationRunner {
private final Logger logger = LoggerFactory.getLogger(ApplicationInit.class);
private final ResourceLoader resourceLoader;
private final VectorStore vectorStore;
private final ElasticsearchClient elasticsearchClient;
private final ElasticsearchVectorStoreProperties options;
private static final String textField = "content";
private static final String vectorField = "embedding";
public ApplicationInit(
ResourceLoader resourceLoader,
VectorStore vectorStore,
ElasticsearchClient elasticsearchClient,
ElasticsearchVectorStoreProperties options
) {
this.resourceLoader = resourceLoader;
this.vectorStore = vectorStore;
this.elasticsearchClient = elasticsearchClient;
this.options = options;
}
@Override
public void run(ApplicationArguments args) {
// 1. load pdf resources.
List<Resource> pdfResources = loadPdfResources();
// 2. parse pdf resources to Documents.
List<Document> documents = parsePdfResource(pdfResources);
// 3. import to ES.
importToES(documents);
logger.info("RAG application init finished");
}
private List<Resource> loadPdfResources() {
List<Resource> pdfResources = new ArrayList<>();
try {
logger.info("加载 PDF 资源=================================");
ResourcePatternResolver resolver = (ResourcePatternResolver) resourceLoader;
Resource[] resources = resolver.getResources("classpath:data" + "/*.pdf");
for (Resource resource : resources) {
if (resource.exists()) {
pdfResources.add(resource);
}
}
logger.info("加载 PDF 资源完成=================================");
}
catch (Exception e) {
throw new RuntimeException("Failed to load PDF resources", e);
}
return pdfResources;
}
private List<Document> parsePdfResource(List<Resource> pdfResources) {
List<Document> resList = new ArrayList<>();
logger.info("开始解析 PDF 资源=================================");
for (Resource springAiResource : pdfResources) {
// 1. parse document
DocumentReader reader = new PagePdfDocumentReader(springAiResource);
List<Document> documents = reader.get();
logger.info("{} documents loaded", documents.size());
// 2. split trunks
List<Document> splitDocuments = new TokenTextSplitter().apply(documents);
logger.info("{} documents split", splitDocuments.size());
// 3. add res list
resList.addAll(splitDocuments);
}
logger.info("解析 PDF 资源完成=================================");
return resList;
}
private void importToES(List<Document> documents) {
logger.info("开始导入数据到 ES =================================");
logger.info("create embedding and save to vector store");
createIndexIfNotExists();
vectorStore.add(documents);
logger.info("导入数据到 ES 完成=================================");
}
private void createIndexIfNotExists() {
try {
String indexName = options.getIndexName();
Integer dimsLength = options.getDimensions();
if (!StringUtils.hasText(indexName)) {
throw new IllegalArgumentException("Elastic search index name must be provided");
}
boolean exists = elasticsearchClient.indices().exists(idx -> idx.index(indexName)).value();
if (exists) {
logger.debug("Index {} already exists. Skipping creation.", indexName);
return;
}
String similarityAlgo = options.getSimilarity().name();
IndexSettings indexSettings = IndexSettings
.of(settings -> settings.numberOfShards(String.valueOf(1)).numberOfReplicas(String.valueOf(1)));
Map<String, Property> properties = new HashMap<>();
properties.put(vectorField, Property.of(property -> property.denseVector(
DenseVectorProperty.of(dense -> dense.index(true).dims(dimsLength).similarity(similarityAlgo)))));
properties.put(textField, Property.of(property -> property.text(TextProperty.of(t -> t))));
Map<String, Property> metadata = new HashMap<>();
metadata.put("ref_doc_id", Property.of(property -> property.keyword(KeywordProperty.of(k -> k))));
properties.put("metadata",
Property.of(property -> property.object(ObjectProperty.of(op -> op.properties(metadata)))));
CreateIndexResponse indexResponse = elasticsearchClient.indices()
.create(createIndexBuilder -> createIndexBuilder.index(indexName)
.settings(indexSettings)
.mappings(TypeMapping.of(mappings -> mappings.properties(properties))));
if (!indexResponse.acknowledged()) {
throw new RuntimeException("failed to create index");
}
logger.info("create elasticsearch index {} successfully", indexName);
}
catch (IOException e) {
logger.error("failed to create index", e);
throw new RuntimeException(e);
}
}
}
AIRagService
在此文件中,执行用户问题的查询。主要的任务是:
- 加载 prompt 模板,接受用户的 prompt;
- 执行向量相似性检索,获得向量上下文;
- 调用模型,获得输出。(deepseek-r1 有 thinking 过程,既 Ressoning Content)
@Service
public class AIRagService {
private final Logger logger = LoggerFactory.getLogger(AIRagService.class);
@Value("classpath:/prompts/system-qa.st")
private Resource systemResource;
private final ChatModel ragChatModel;
private final ChatClient ragClient;
private final VectorStore vectorStore;
private static final String textField = "content";
public AIRagService(
ChatModel chatModel,
// 使用 DashScope ChatModel
// @Qualifier("dashscopeChatModel") ChatModel chatModel,
VectorStore vectorStore
) {
this.ragChatModel = chatModel;
this.vectorStore = vectorStore;
this.ragClient = ChatClient.builder(ragChatModel)
.defaultAdvisors((new QuestionAnswerAdvisor(vectorStore)))
.build();
}
public Flux<String> retrieve(String prompt) {
// Get the vector store prompt tmpl.
String promptTemplate = getPromptTemplate(systemResource);
// Enable hybrid search, both embedding and full text search
SearchRequest searchRequest = SearchRequest.builder().
topK(4)
.similarityThresholdAll()
.filterExpression(
new FilterExpressionBuilder()
.eq(textField, prompt).build()
).build();
// Build ChatClient with retrieval rerank advisor:
// ChatClient runtimeChatClient = ChatClient.builder(chatModel)
// .defaultAdvisors(new RetrievalRerankAdvisor(vectorStore, rerankModel, searchRequest, promptTemplate, 0.1))
// .build();
// Spring AI RetrievalAugmentationAdvisor
// Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
// .queryTransformers(RewriteQueryTransformer.builder()
// .chatClientBuilder(ChatClient.builder(ragChatModel).build().mutate())
// .build())
// .documentRetriever(VectorStoreDocumentRetriever.builder()
// .similarityThreshold(0.50)
// .vectorStore(vectorStore)
// .build())
// .build();
// Retrieve and llm generate
// return ragClient.prompt()
// .advisors(retrievalAugmentationAdvisor)
// .user(prompt)
// .stream()
// .content();
return ChatClient.builder(ragChatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore, searchRequest, promptTemplate))
.user(prompt)
.stream()
.content();
}
private String getPromptTemplate(Resource systemResource) {
try {
logger.info("Loading system resource: {}", systemResource.getURI());
return systemResource.getContentAsString(StandardCharsets.UTF_8);
}
catch (IOException e) {
throw new RuntimeException(e);
}
}
}
同时,根据代码中的注释,也可以使用 Spring AI Alibaba 提供的 Rerank 重排序实现,提高检索精度。
调用效果如下:(画线之前为 deepseek 的思考过程)
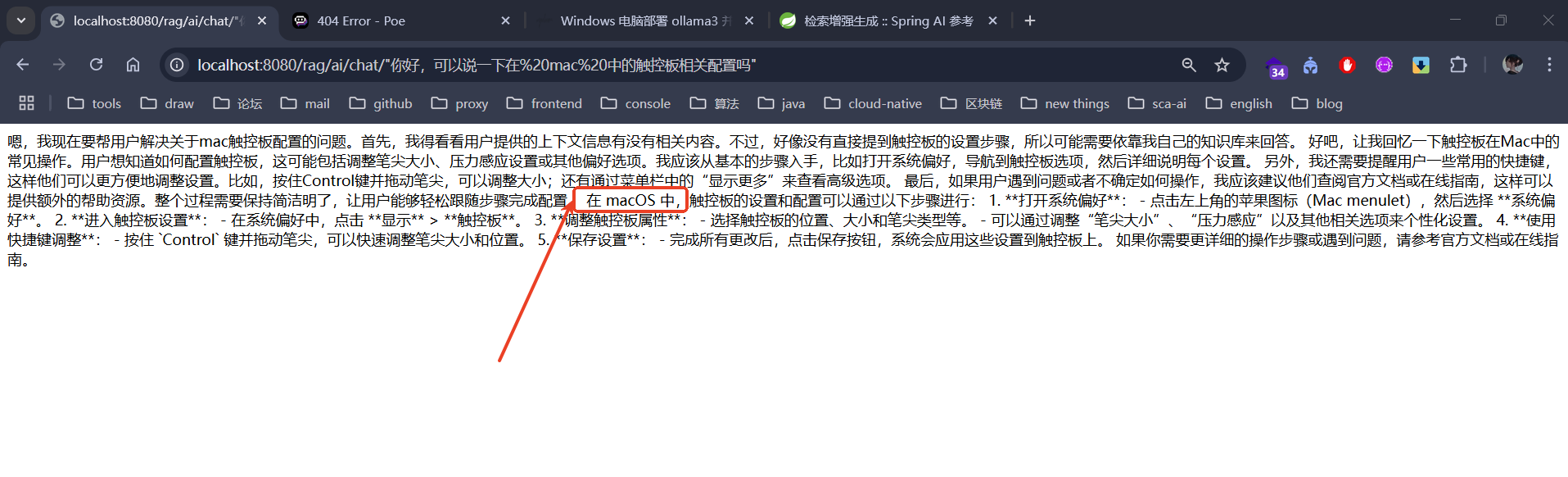
适配 Spring AI Alibaba DashScope
引入 spring-ai-alibaba-starter
<!-- Spring AI Alibaba DashScope -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M5.1</version>
</dependency>
在配置文件中加入以下配置:(确保同时只能有一个模型注入到 IOC 容器中,需要关闭其他 chat 和 embedding 模型的注入)
spring:
application:
name: ollama-rag
ai:
dashscope:
api-key: ${AI_DASHSCOPE_API_KEY}
chat:
options:
model: deepseek-r1
embedding:
enabled: false
ollama:
base-url: http://127.0.0.1:11434
chat:
model: deepseek-r1:8b
enabled: false
embedding:
model: nomic-embed-text:latest
vectorstore:
elasticsearch:
index-name: ollama-rag-embedding-index
similarity: cosine
dimensions: 768
elasticsearch:
uris: http://127.0.0.1:9200
在 service 中注入 DashScopeChatModel
public AIRagService(
// ChatModel chatModel,
// 使用 DashScope ChatModel
@Qualifier("dashscopeChatModel") ChatModel chatModel,
VectorStore vectorStore
) {
this.ragChatModel = chatModel;
this.vectorStore = vectorStore;
this.ragClient = ChatClient.builder(ragChatModel)
.defaultAdvisors((new QuestionAnswerAdvisor(vectorStore)))
.build();
}
调用效果如下:(Spring AI Alibaba 1.0.0-M5.1 不支持 reasoning content 透出,在 M6 中支持)
