本文同步发布在 spring ai alibaba blog 和阿里云公众号
Spring AI 实现了模块化 RAG 架构,架构的灵感来自于论文“模块化 RAG:将 RAG 系统转变为类似乐高的可重构框架”中详述的模块化概念。
Spring AI 模块化 RAG 体系
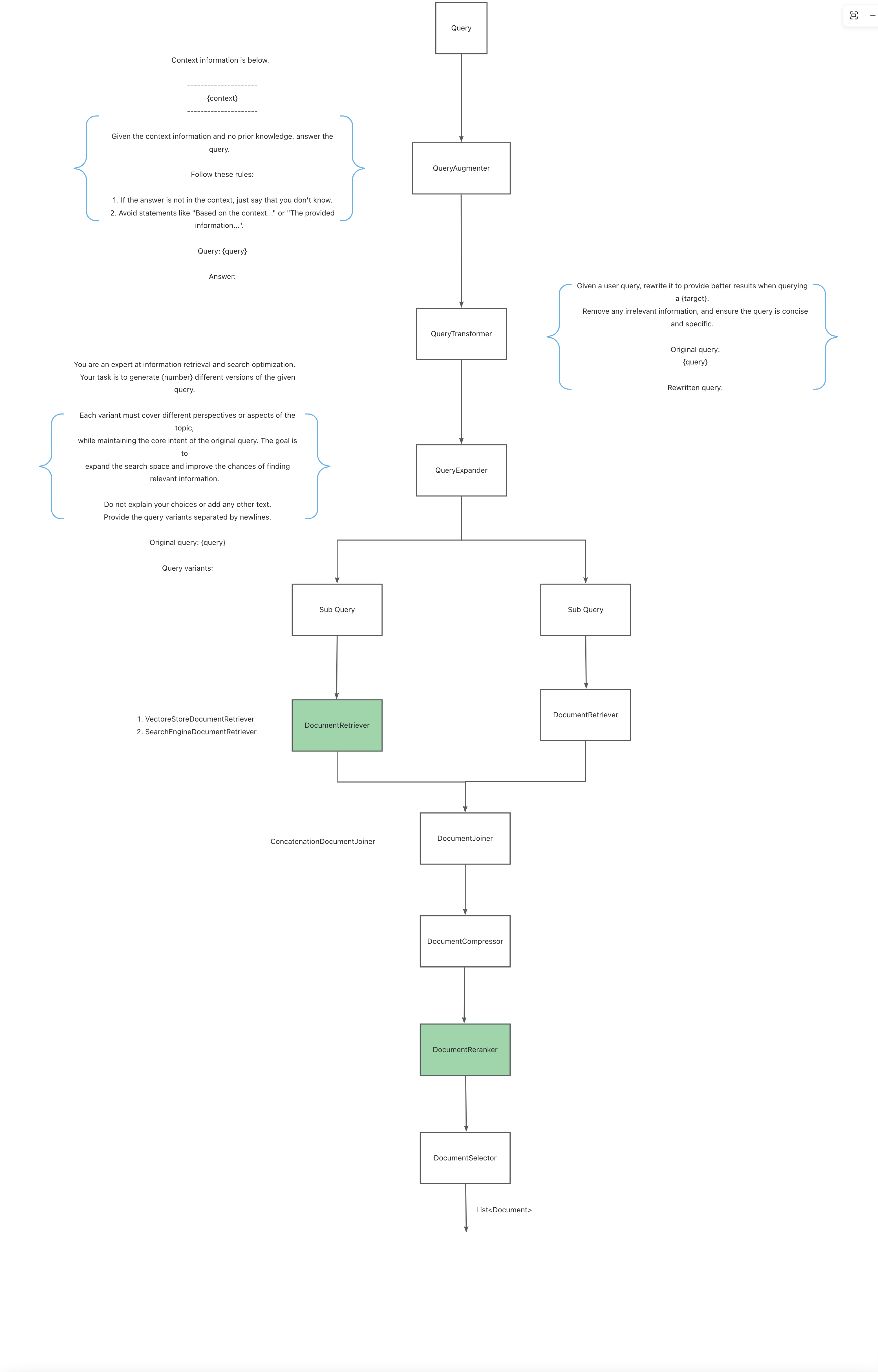
总体上分为以下几个步骤:
Pre-Retrieval
增强和转换用户输入,使其更有效地执行检索任务,解决格式不正确的查询、query 语义不清晰、或不受支持的语言等。
- QueryAugmenter 查询增强:使用附加的上下文数据信息增强用户 query,提供大模型回答问题时的必要上下文信息;
- QueryTransformer 查询改写:因为用户的输入通常是片面的,关键信息较少,不便于大模型理解和回答问题。因此需要使用 prompt 调优手段或者大模型改写用户 query;
- QueryExpander 查询扩展:将用户 query 扩展为多个语义不同的变体以获得不同视角,有助于检索额外的上下文信息并增加找到相关结果的机会。
Retrieval
负责查询向量存储等数据系统并检索和用户 query 相关性最高的 Document。
- DocumentRetriever:检索器,根据 QueryExpander 使用不同的数据源进行检索,例如 搜索引擎、向量存储、数据库或知识图等;
- DocumentJoiner:将从多个 query 和从多个数据源检索到的 Document 合并为一个 Document 集合;
Post-Retrieval
负责处理检索到的 Document 以获得最佳的输出结果,解决模型中的中间丢失和上下文长度限制等。
- DocumentRanker:根据 Document 和用户 query 的相关性对 Document 进行排序和排名;
- DocumentSelector:用于从检索到的 Document 列表中删除不相关或冗余文档;
- DocumentCompressor:用于压缩每个 Document,减少检索到的信息中的噪音和冗余。
生成
生成用户 Query 对应的大模型输出。
Web Search 实践
接下来,将演示如何使用 Spring AI Alibaba 和阿里云 IQS 服务搭建联网搜索 RAG 的实现。
资源准备
DashScope apiKey:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
阿里云 IQS 服务 apiKey:https://help.aliyun.com/product/2837261.html
Pre-Retrieval
将用户 Query 使用 qwen-plus 大模型进行增强改写。
CustomContextQueryAugmenter.java
public class CustomContextQueryAugmenter implements QueryAugmenter {
// 定义 prompt tmpl。
private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate(
// ......
);
private static final PromptTemplate DEFAULT_EMPTY_PROMPT_TEMPLATE = new PromptTemplate(
// ...
);
@NotNull
@Override
public Query augment(
@Nullable Query query,
@Nullable List<Document> documents
) {
// 1. collect content from documents.
AtomicInteger idCounter = new AtomicInteger(1);
String documentContext = documents.stream()
.map(document -> {
String text = document.getText();
return "[[" + (idCounter.getAndIncrement()) + "]]" + text;
})
.collect(Collectors.joining("\n-----------------------------------------------\n"));
// 2. Define prompt parameters.
Map<String, Object> promptParameters = Map.of(
"query", query.text(),
"context", documentContext
);
// 3. Augment user prompt with document context.
return new Query(this.promptTemplate.render(promptParameters));
}
// 当上下文为空时,返回 DEFAULT_EMPTY_PROMPT_TEMPLATE
private Query augmentQueryWhenEmptyContext(Query query) {
if (this.allowEmptyContext) {
logger.debug("Empty context is allowed. Returning the original query.");
return query;
}
logger.debug("Empty context is not allowed. Returning a specific query for empty context.");
return new Query(this.emptyPromptTemplate.render());
}
public static final class Builder {
// ......
}
}
QueryTransformer 配置 bean,用于 rewrite 用户 query:
@Bean
public QueryTransformer queryTransformer(
ChatClient.Builder chatClientBuilder,
@Qualifier("transformerPromptTemplate") PromptTemplate transformerPromptTemplate
) {
ChatClient chatClient = chatClientBuilder.defaultOptions(
DashScopeChatOptions.builder()
.withModel("qwen-plus")
.build()
).build();
return RewriteQueryTransformer.builder()
.chatClientBuilder(chatClient.mutate())
.promptTemplate(transformerPromptTemplate)
.targetSearchSystem("联网搜索")
.build();
}
QueryExpander.java 查询变体
public class MultiQueryExpander implements QueryExpander {
private static final Logger logger = LoggerFactory.getLogger(MultiQueryExpander.class);
private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate(
// ...
);
@NotNull
@Override
public List<Query> expand(@Nullable Query query) {
// ...
String resp = this.chatClient.prompt()
.user(user -> user.text(this.promptTemplate.getTemplate())
.param("number", this.numberOfQueries)
.param("query", query.text()))
.call()
.content();
// ...
List<String> queryVariants = Arrays.stream(resp.split("\n")).filter(StringUtils::hasText).toList();
if (CollectionUtils.isEmpty(queryVariants) || this.numberOfQueries != queryVariants.size()) {
return List.of(query);
}
List<Query> queries = queryVariants.stream()
.filter(StringUtils::hasText)
.map(queryText -> query.mutate().text(queryText).build())
.collect(Collectors.toList());
// 是否引入原查询
if (this.includeOriginal) {
logger.debug("Including original query in the expanded queries for query: {}", query.text());
queries.add(0, query);
}
return queries;
}
public static final class Builder {
// ......
}
}
Retrieval
从不同数据源查询和用户 query 相似度最高的数据。(这里使用 Web Search)
WebSearchRetriever.java
public class WebSearchRetriever implements DocumentRetriever {
// 注入 IQS 搜索引擎
private final IQSSearchEngine searchEngine;
@NotNull
@Override
public List<Document> retrieve(
@Nullable Query query
) {
// 搜索
GenericSearchResult searchResp = searchEngine.search(query.text());
// 清洗数据,将数据转换为 Spring AI 的 Document 对象
List<Document> cleanerData = dataCleaner.getData(searchResp);
logger.debug("cleaner data: {}", cleanerData);
// 返回结果
List<Document> documents = dataCleaner.limitResults(cleanerData, maxResults);
logger.debug("WebSearchRetriever#retrieve() document size: {}, raw documents: {}",
documents.size(),
documents.stream().map(Document::getId).toArray()
);
return enableRanker ? ranking(query, documents) : documents;
}
private List<Document> ranking(Query query, List<Document> documents) {
if (documents.size() == 1) {
// 只有一个时,不需要 rank
return documents;
}
try {
List<Document> rankedDocuments = documentRanker.rank(query, documents);
logger.debug("WebSearchRetriever#ranking() Ranked documents: {}", rankedDocuments.stream().map(Document::getId).toArray());
return rankedDocuments;
} catch (Exception e) {
// 降级返回原始结果
logger.error("ranking error", e);
return documents;
}
}
public static final class Builder {
// ...
}
}
DocumentJoiner.java 合并 Document
public class ConcatenationDocumentJoiner implements DocumentJoiner {
@NotNull
@Override
public List<Document> join(
@Nullable Map<Query, List<List<Document>>> documentsForQuery
) {
// ...
Map<Query, List<List<Document>>> selectDocuments = selectDocuments(documentsForQuery, 10);
Set<String> seen = new HashSet<>();
return selectDocuments.values().stream()
// Flatten List<List<Documents>> to Stream<List<Documents>.
.flatMap(List::stream)
// Flatten Stream<List<Documents> to Stream<Documents>.
.flatMap(List::stream)
.filter(doc -> {
List<String> keys = extractKeys(doc);
for (String key : keys) {
if (!seen.add(key)) {
logger.info("Duplicate document metadata: {}",doc.getMetadata());
// Duplicate keys found.
return false;
}
}
// All keys are unique.
return true;
})
.collect(Collectors.toList());
}
private Map<Query, List<List<Document>>> selectDocuments(
Map<Query, List<List<Document>>> documentsForQuery,
int totalDocuments
) {
Map<Query, List<List<Document>>> selectDocumentsForQuery = new HashMap<>();
int numberOfQueries = documentsForQuery.size();
if (Objects.equals(0, numberOfQueries)) {
return selectDocumentsForQuery;
}
int baseCount = totalDocuments / numberOfQueries;
int remainder = totalDocuments % numberOfQueries;
// To ensure consistent distribution. sort the keys (optional)
List<Query> sortedQueries = new ArrayList<>(documentsForQuery.keySet());
// Other sort
// sortedQueries.sort(Comparator.comparing(Query::getSomeProperty));
Iterator<Query> iterator = sortedQueries.iterator();
for (int i = 0; i < numberOfQueries; i ++) {
Query query = sortedQueries.get(i);
int documentToSelect = baseCount + (i < remainder ? 1 : 0);
List<List<Document>> originalDocuments = documentsForQuery.get(query);
List<List<Document>> selectedNestLists = new ArrayList<>();
int remainingDocuments = documentToSelect;
for (List<Document> documentList : originalDocuments) {
if (remainingDocuments <= 0) {
break;
}
List<Document> selectSubList = new ArrayList<>();
for (Document docs : documentList) {
if (remainingDocuments <= 0) {
break;
}
selectSubList.add(docs);
remainingDocuments --;
}
if (!selectSubList.isEmpty()) {
selectedNestLists.add(selectSubList);
}
}
selectDocumentsForQuery.put(query, selectedNestLists);
}
return selectDocumentsForQuery;
}
private List<String> extractKeys(Document document) {
// 提取 key
return keys;
}
}
Post-Retrieval
处理从联网搜索种获得的 Document,以获得最佳输出。
DashScopeDocumentRanker.java
public class DashScopeDocumentRanker implements DocumentRanker {
// ...
@NotNull
@Override
public List<Document> rank(
@Nullable Query query,
@Nullable List<Document> documents
) {
// ...
try {
List<Document> reorderDocs = new ArrayList<>();
// 由调用者控制文档数
DashScopeRerankOptions rerankOptions = DashScopeRerankOptions.builder()
.withTopN(documents.size())
.build();
if (Objects.nonNull(query) && StringUtils.hasText(query.text())) {
// 组装参数调用 rankModel
RerankRequest rerankRequest = new RerankRequest(
query.text(),
documents,
rerankOptions
);
RerankResponse rerankResp = rerankModel.call(rerankRequest);
rerankResp.getResults().forEach(res -> {
Document outputDocs = res.getOutput();
// 查找并添加到新的 list 中
Optional<Document> foundDocsOptional = documents.stream()
.filter(doc ->
{
// debug rerank output.
logger.debug("DashScopeDocumentRanker#rank() doc id: {}, outputDocs id: {}", doc.getId(), outputDocs.getId());
return Objects.equals(doc.getId(), outputDocs.getId());
})
.findFirst();
foundDocsOptional.ifPresent(reorderDocs::add);
});
}
return reorderDocs;
}
catch (Exception e) {
// 根据异常类型做进一步处理
throw new SAAAppException(e.getMessage());
}
}
}
大模型输出
WebSearchService.java
@Service
public class SAAWebSearchService {
// ...
private static final String DEFAULT_WEB_SEARCH_MODEL = "deepseek-r1";
public SAAWebSearchService(
ChatClient.Builder chatClientBuilder,
QueryTransformer queryTransformer,
QueryExpander queryExpander,
IQSSearchEngine searchEngine,
DataClean dataCleaner,
DocumentRanker documentRanker,
@Qualifier("queryArgumentPromptTemplate") PromptTemplate queryArgumentPromptTemplate
) {
this.queryTransformer = queryTransformer;
this.queryExpander = queryExpander;
this.queryArgumentPromptTemplate = queryArgumentPromptTemplate;
// 用于 DeepSeek-r1 的 reasoning content 整合到输出中
this.reasoningContentAdvisor = new ReasoningContentAdvisor(1);
// 构建 chatClient
this.chatClient = chatClientBuilder
.defaultOptions(
DashScopeChatOptions.builder()
.withModel(DEFAULT_WEB_SEARCH_MODEL)
// stream 模式下是否开启增量输出
.withIncrementalOutput(true)
.build())
.build();
// 日志
this.simpleLoggerAdvisor = new SimpleLoggerAdvisor(100);
this.webSearchRetriever = WebSearchRetriever.builder()
.searchEngine(searchEngine)
.dataCleaner(dataCleaner)
.maxResults(2)
.enableRanker(true)
.documentRanker(documentRanker)
.build();
}
// 处理用户输入
public Flux<String> chat(String prompt) {
return chatClient.prompt()
.advisors(
createRetrievalAugmentationAdvisor(),
// 整合到 reasoning content 输出中
reasoningContentAdvisor,
simpleLoggerAdvisor
).user(prompt)
.stream()
.content();
}
// 创建 advisor
private RetrievalAugmentationAdvisor createRetrievalAugmentationAdvisor() {
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(webSearchRetriever)
.queryTransformers(queryTransformer)
.queryAugmenter(
new CustomContextQueryAugmenter(
queryArgumentPromptTemplate,
null,
true)
).queryExpander(queryExpander)
.documentJoiner(new ConcatenationDocumentJoiner())
.build();
}
}
演示
使用问题 杭州有什么推荐旅游的地方吗 为例。
普通输出
### 必游景点
1. **西湖**
- **核心特色**:杭州的标志性景点,包含“西湖十景”(如苏堤春晓、断桥残雪、三潭印月等),可泛舟湖上或沿湖骑行。
- **推荐活动**:夜游西湖灯光秀、漫步白堤/苏堤。
2. **灵隐寺与飞来峰**
- **文化价值**:千年古刹灵隐寺被誉为“东南佛国”,飞来峰的摩崖石刻为宋代佛教艺术瑰宝。
---
### 自然与生态
1. **西溪国家湿地公园**
- **亮点**:国内首个国家湿地公园,可乘摇橹船游览,春秋季观芦苇、赏梅花。
2. **九溪十八涧**
- **特色**:茶园、溪流、古树构成的徒步路线,适合夏季避暑。
---
### 文化体验
1. **宋城景区**
- **必看演出**:《宋城千古情》通过歌舞演绎杭州历史,沉浸式体验南宋文化。
2. **中国茶叶博物馆(龙井馆)**
- **体验**:了解龙井茶文化,参与采茶、制茶活动,品鉴正宗西湖龙井。
---
### 美食街区
1. **河坊街**
- **推荐小吃**:葱包桧、定胜糕、西湖醋鱼、东坡肉。
2. **武林夜市**
- **特色**:本地人常去的夜宵聚集地,汇聚浙江风味与网红美食。
---
### 温馨提示
- **最佳季节**:春季(3-5月)赏桃柳,秋季(9-11月)观桂花。
- **交通建议**:西湖周边景点集中,建议骑行或步行;地铁1号线覆盖主城区。
如需更详细的行程规划,可补充具体需求(如亲子游、摄影主题等)。
联网搜索输出
### 杭州旅游推荐
#### 1. 西湖风景区
杭州的核心景点,包含断桥残雪、苏堤春晓等经典景观,四季景色各异,适合漫步或乘船游览。清晨和傍晚的光线最佳,湖光山色与人文遗迹交融,是摄影和休闲的首选 [2][3][6]。
#### 2. 灵隐寺
千年古刹隐于山林,古木参天,佛教氛围浓厚。寺内素斋体验和祈福活动值得尝试,适合寻求宁静的游客 [2][5][6]。
#### 3. 西溪国家湿地公园
城市内的生态绿肺,河道纵横,可乘船观赏湿地风光,偶遇白鹭等水鸟。春季踏青、秋季赏芦的绝佳地 [2][3][6]。
#### 4. 天竺三寺
位于西湖区灵隐寺附近,由三座历史悠久的寺庙组成,建筑风格独特,环境清幽,适合文化探访和秋日游览 [1]。
#### 5. 杭州宋城
以宋代风貌为主题的景区,可换古装沉浸式体验市井生活,大型演出《宋城千古情》融合历史与艺术,视觉震撼 [2][5]。
#### 6. 河坊街
古色古香的商业街,聚集传统小吃、手工艺品店,可品尝葱包桧、定胜糕等美食,适合拍摄人文题材照片 [2][3][5]。
#### 7. 千岛湖风景区
以1078座岛屿闻名,梅峰岛观景台可俯瞰全景,湖光山色如画卷。适合自驾游和山水摄影 [3][6]。
#### 8. 茅家埠景区
西湖边的隐逸之地,春季樱花与湖柳相映,秋季芦苇摇曳,人少景美,适合徒步和自然摄影 [1][3]。
#### 9. 九溪烟树(九溪十八涧)
山涧、茶园与枫叶交织的徒步路线,秋季红叶似火,溪水潺潺,充满诗意 [2][6]。
#### 10. 太子湾公园
春季郁金香、樱花盛开,色彩斑斓,是热门打卡地。适合家庭游和花卉摄影 [2][3]。
---
**其他推荐**
- **浙西大龙湾**:自然峡谷与瀑布群,夏季漂流项目刺激 [1]。
- **中国印学博物馆**:展示印章文化与历史,适合文化爱好者 [1]。
- **塘栖古镇**:运河畔的江南水乡,保留明清建筑与民俗风情 [3][6]。
**旅行提示**
- 西湖、灵隐寺等热门景点建议提前预约门票 [5]。
- 春季多雨,需携带雨具;秋季适合户外活动 [2][5]。
(参考文档:[1][2][3][5][6])