大模型专栏--大模型应用场景
紧接着第一篇,什么是大模型,这篇文章讨论一下大模型的应用场景和应用方式有哪些?
基础使用
随着 GPT 的出现,AI 大模型已经越来越多得出现在日常生活和学术研究,工作中。
按照使用方向有以下几种:
- 自然语言处理:翻译、文字理解、聊天机器人、情感分析、文本生成和语义分析等。
- 多模态:图像识别、图像生成、图像增强、人脸识别,文本和语音之间的转换。
- 代码模型:生成单元测试,添加注释,解释代码。例如 IDEA 的各种插件,比较出名的有 Github Copilot,通义千问插件等。
- 文档处理:将大量文档数据输入给大模型,让大模型充当客服助手,生成文案等,其本质也算是自然语言处理。
上述内容是大模型在实际应用的最终表现形式。那么这些最终产品是怎么构建出来的?在那里使用到了大模型?
进阶使用
RAG
RAG 全称为:Retrieval-Augmented Generation,检索增强生成。
随着大模型的发展,其已经被用于到业务场景中。但是目前也存在一些较为突出的问题。
- 领域知识缺乏:大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。模型难以处理实时信息,因为训练过程耗时严重且成本较高。模型一旦训练完成,就难以获取和处理新信息。
- 数据安全:在企业内部,数据安全至关重要,没有企业愿意把自身数据上传到第三方平台训练大模型。
- 偏见问题:和第一篇文章类似,模型的回答基于大模型,其底层是一系列复杂的数值计算。有时候也会正儿八经的胡说八道。
RAG 技术通过引入外部知识库,利用检索模块从大量文档中提取相关信息,并将这些信息传递给生成模块,从而生成更准确且有用的回答。也是当今大模型最火的应用方案。
RAG 原理图如下:
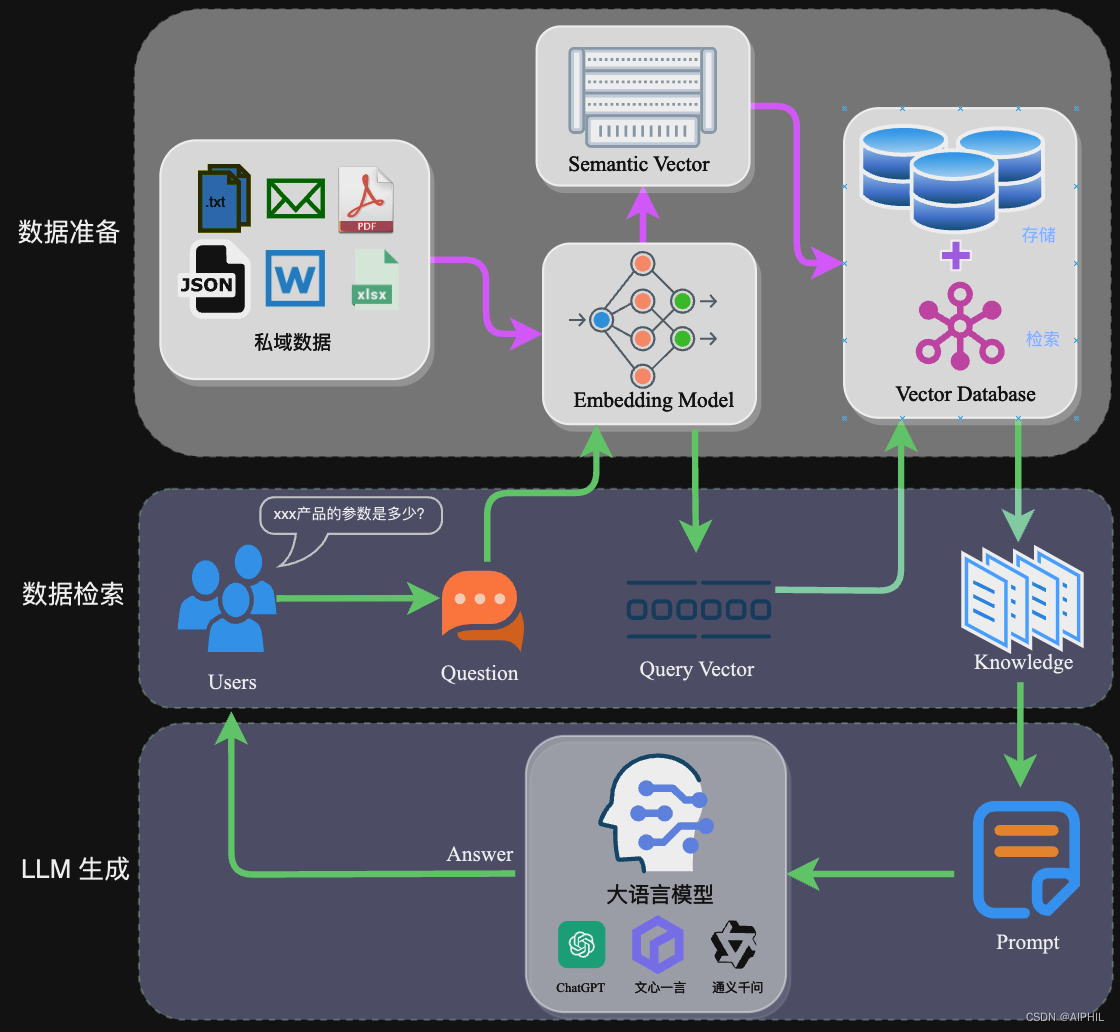
通过检索技术获取相关的知识,然后融入 Prompt 中,让大模型能够参考相应的知识从而给出合理回答。因此,可以将 RAG 的核心理解为 “检索+生成”。前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
流程大致为:
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入 Prompt——>LLM 生成答案
应用场景为:
- 私域知识库;
- 客服助手等。
Agent
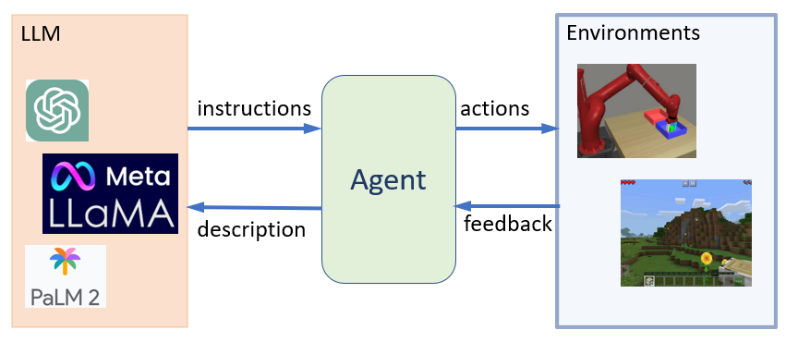
如果你看过钢铁侠,你肯定对钢铁侠的助手——贾维斯 不陌生。其便是最经典的 Agent 例子。
Agent 的定义如下:是一种构建于大型语言模型(LLM)之上的智能体,它具备环境感知能力、自主理解、决策制定及执行行动的能力。
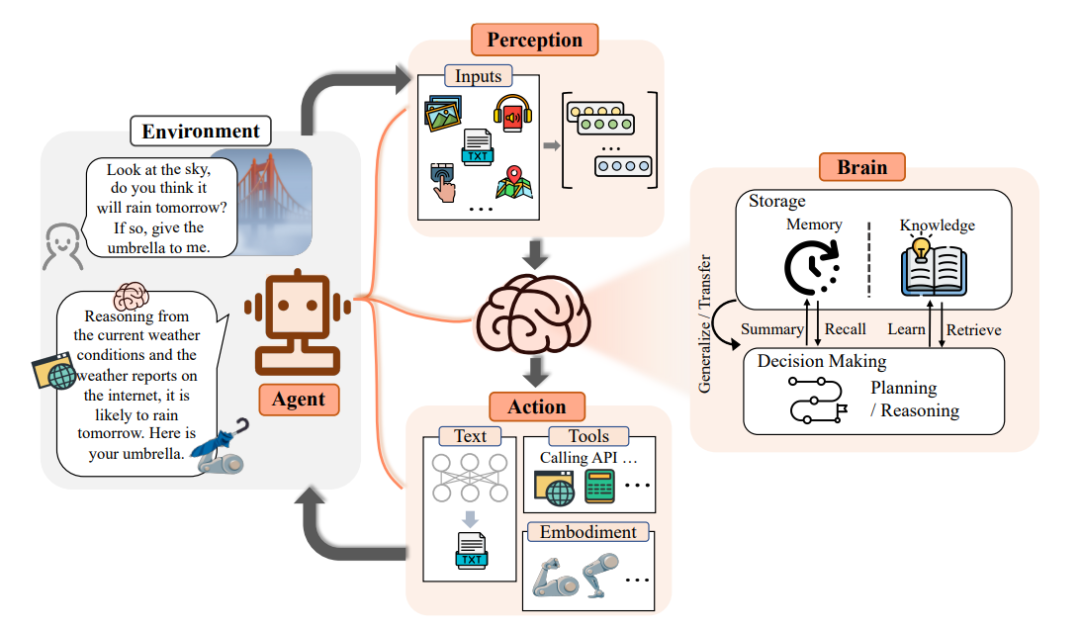
智能体能够模拟思维过程,灵活调用各种预定义的 Tools 工具,逐步达成想要实现的目标。
其大致可以分为如下步骤:
- 感知(Perception):输入(Prompt)和外部环境(Env)
- 信息处理(Agent 大脑 Brains)
- 信息存储:Store & memory
- 大模型对信息进行处理(基于感知)
- 指定计划(Planning):做出具体性的响应计划
- 执行(Action):调用 Tools 或者 Function Calling 调用外部 API
- 输出(Output):输出 Agent 执行的结果
一个使用场景:
- 感知:我今天有点发烧,昨晚没有盖好被子并且天气很冷;
- 信息存储:基于 memory 发现有没有类型记录或者基础疾病等信息;
- 大模型:基于感知推断,感冒了;
- 指定计划:需要请假打车去看病,写好假条,叫好车等;
- 执行:调用请假和打车API(Tools) 和 app 交互完成一系列动作;
- 输出:已经帮您写好了假条打好了车。
AGI
AGI(通用人工智能)是 AI 发展的终极目标,是让智能系统具备像人类一样理解和处理各种复杂情况与任务的能力。在实现过程中,AI 大模型、Prompt Engineering、Agent 智能体、知识库、向量数据库、RAG 和其他关键技术扮演着至关重要的角色。这些技术元素在多样化的形态中相互协作,推动 AI 技术持续向前发展。